3 Fundamentos Geo-DBMS e Indice
Esta lección discutirá los conceptos de gestión de transacciones en un DBMS. Esta es una tarea importante al actualizar o insertar datos en un DBMS. La gestión de transacciones es simple en un entorno de usuario único. Sin embargo, si más de un usuario puede actualizar los mismos datos al mismo tiempo, nos encontramos con problemas. La gestión de transacciones ofrece algoritmos para detectar y resolver conflictos de concurrencia.
3.1 ¿Qué es un Geo-DBMS?
Los sistemas de gestión de bases de datos relacionales son sistemas eficientes para manejar grandes conjuntos de datos no espaciales. Son altamente resistentes a las fallas, permiten el acceso concurrente a los datos para muchos usuarios y proporcionan algoritmos de búsqueda eficientes para grandes conjuntos de datos. El objetivo de las primeras 6 lecciones fue abordar estas características de DBMS.
Sin embargo, los DBMS convencionales no son eficientes en el manejo de datos espaciales. Un DBMS ordinario no es capaz de manejar consultas espaciales como Listar los nombres de todas las librerías dentro de diez millas de la ciudad de Salzburgo o Listar todos los clientes que viven en la provincia de Salzburgo y sus provincias vecinas.
Un Geo-DBMS tiene toda la funcionalidad de un DBMS relacional ordinario. Además, es capaz de manejar eficientemente datos espaciales. Se basa en el enfoque objeto-relacional para almacenar, manipular, indexar, consultar y analizar datos espaciales en un DBMS. El modelado de objetos espaciales discretos está por lo tanto más cerca de la naturaleza de los conceptos de DBMS relacionales y objeto-relacionales.
Siva Ravada de Oracle proporciona una visión general excelente y legible de las características particulares de las bases de datos espaciales y los desafíos que plantean en Geo-DBMS. Lea el artículo de Ravada para complementar el contenido de esta lección GeoSpatial World
Los Geo-DBMS más potentes son las plataformas de código abierto PostGIS (la extensión espacial de PostgreSQL) y SpatiaLite (la extensión espacial de SQLite), así como el DBMS Oracle Spatial patentado. En contraste, las bases de datos ráster y las series de tiempo ráster (cubos de datos) se han desarrollado más tarde y actualmente son un campo de rápido crecimiento en la investigación de bases de datos y la industria.
Geo-DBMS se centra en:
- almacenamiento eficiente, consultas, intercambio de grandes conjuntos de datos espaciales
- operaciones de consulta simples basadas en conjuntos, por ejemplo: búsqueda por región, superposición, vecino más cercano, distancia, adyacencia, perímetro
- utiliza índices espaciales y optimización de consultas para acelerar las consultas sobre grandes conjuntos de datos espaciales.
El valor agregado de usar un Geo-DBMS dentro de un SIG lo proporcionan todos los puntos fuertes específicos de DBMS como escalabilidad, seguridad de fallas, seguridad de acceso, gestión de procesos, integridad, gestión de transacciones, etc. DBMS incluyendo Oracle, Postgre o SpatiaLite. Sin embargo, Geo-DBMS también puede ser utilizado por otras aplicaciones. De hecho, como observación general, Geo-DBMS utiliza cada vez más los datos espaciales, fuera de un SIG.
3.2 Esquemas para almacenar datos espaciales en un DBMS
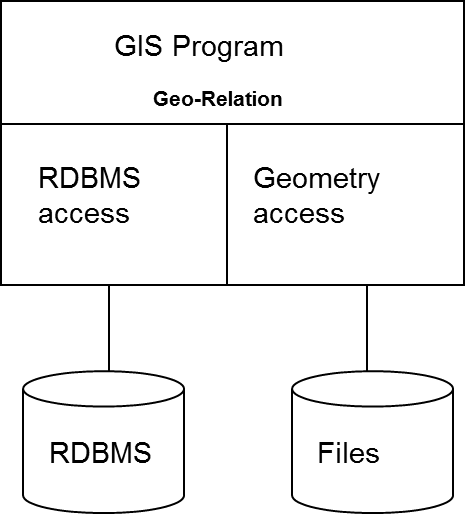
3.2.1 Modelo ligeramente acoplado (Loosely coupled model)
En un modelo ligeramente acoplado, la relación entre los datos de atributos alfanuméricos y la geometría se establece a través de un enlace relacional. Los primeros SIG habían implementado sus propias soluciones de bases de datos de acuerdo con este modelo débilmente acoplado. Al día de hoy, los sistemas SIG complementan este enfoque tradicional con interfases para el software DBMS.
La relación de acoplamiento flexible está bien si solo necesita un sistema de análisis espacial sin requisitos de interfaz sofisticados y sin requisitos especiales de escalabilidad y seguridad (Figura 3.1).
3.2.2 Objetos grandes (BLOB)
Con la implementación de objetos binarios grandes (campos BLOB), DBMS de repente obtuvo la capacidad de almacenar grandes cantidades de datos binarios en un campo. Para la industria de SIG, significaba que el almacenamiento integrativo de datos espaciales (Geometrías Y Atributos) se puede hacer fácilmente en un DBMS y GIS podría utilizar todas las ventajas de la gestión de datos basada en DBMS almacenando todos los datos en un DBMS.
Con el fin de evitar el peligro de enviar un formato de datos propietario a BLOB, el ISO / TC211 definió la estructura de las geometrías basadas en el concepto de geometría binaria bien conocida en ISO 19125.
Ventajas
- Los objetos grandes proporcionan la capacidad de almacenar los atributos y las geometrías juntas en el DBMS.
- Para los proveedores de SIG, es fácil implementar estructuras de datos de geometría en BLOB. Básicamente, solo necesitan proyectar la estructura de datos basada en archivos en un campo binario.
- El concepto basado en BLOB para almacenar objetos espaciales se puede implementar en cada base de datos que admita esos objetos de campo grandes, incluso en herramientas como MS Access.
Desventajas
- Solo se puede aplicar un subconjunto de la funcionalidad DBMS a los BLOB (incluso las restricciones disminuyen)
- Faltan funciones como replicación, carga masiva o capacidades DML basadas en SQL.
- Por lo tanto, el análisis espacial y la manipulación de datos requieren principalmente una capa de aplicación adicional para trabajar con el enfoque patentado de DBMS.
- La estructura puede no ser transparente para un usuario (si no se define conforme a la ISO 19125)
- Para implementar una funcionalidad personalizada, es necesaria una interfaz de programación específica que pueda acceder a los datos específicos en el BLOB
3.2.3 Modelo relacional para geometría
El modelo relacional para almacenar geometría está, como su nombre lo indica, completamente basado en el modelo relacional. Para almacenar un objeto espacial en un DBMS, la geometría debe descomponerse en sus partes atómicas (descomposición jerárquica).
| Census_blocks | |||
| Name | Area | Population | boundary-ID |
| 340 | 1 | 1839 | 1050 |
| Polygon | |
| boundary-ID | edge-name |
| 1050 | A |
| 1050 | B |
| 1050 | C |
| 1050 | D |
| Edge | |
| edge-name | endpoint |
| A | 1 |
| A | 2 |
| B | 2 |
| B | 3 |
| C | 3 |
| C | 4 |
| D | 4 |
| D | 1 |
| Point | ||
| endpoint | x-coor | y-coor |
| 1 | 0 | 1 |
| 2 | 0 | 0 |
| 3 | 1 | 0 |
| 4 | 1 | 1 |
El ejemplo muestra un bloque censal:
- Un bloque de censo puede estar compuesto por muchos polígonos (puede contener agujeros, puede ser disjunto) -> Tabla POLIGONO.
- Los polígonos se componen de bordes (segmentos de línea) -> Tabla EDGE.
- Los bordes están compuestos de nodos / puntos -> Tabla de PUNTOS.
- El enlace entre las partes de geometría se modela en base a un modelo de datos relacionales para geometría.
Ventajas
- Los modelos relacionales evitan la redundancia de datos. Si se basa en conceptos topológicos (que era / es el caso para algunos modelos), proporcionan un modelo optimizado para análisis o consultas topológicos. Los modelos relacionales permiten el almacenamiento de objetos espaciales vinculados topológicamente.
Desventajas
- El principal problema es que se necesita más de una tabla para almacenar datos espaciales. Esto tiene algunos impactos negativos en el rendimiento y hace que la implementación específica de proyectos de modelos de datos sea bastante engorrosa.
3.2.4 DBMS Orientadas a Objetos (modelo OR)
Las DBMS orientadas a objetos están marcados desde el estándar ISO SQL: 1999. Este enfoque combina la solidez de los conceptos relacionales probados con la flexibilidad y las capacidades mejoradas proporcionadas por la metodología orientada a objetos (Figura 3.2).
- En la práctica, la orientación a objetos ofrece la capacidad de definir de manera flexible nuevos tipos de datos (encapsulación de tipos de datos existentes en nuevos tipos de datos). Debido a la importancia de la gestión de datos espaciales, la mayoría de los proveedores de OR-DBMS ya ofrecen tipos de datos espaciales “construidos en fábrica”. En teoría, el usuario puede incluso implementar su propio tipo de datos espaciales (o incluso un modelo espacial).
Objeto relacional significa:
- Fusión de orientación a objetos y gestión de datos relacionales
- Nuevos tipos de datos con paradigma orientado a objetos
- Suministro de tipos de datos espaciales
- Los tipos de datos pueden ser definidos por el usuario
El modelo OR básicamente elimina las principales desventajas de los modelos discutidos anteriormente. Actualmente es el estado del arte para el procesamiento espacial de DBMS y permite una integración completa de espacial en el paradigma de computación empresarial orientado a DBMS.
Ventajas
- Almacenamiento integrador de objetos espaciales.
- La geometría se modela en un tipo de datos orientada a objetos
- Estructura de tabla simple (solo necesita una tabla para describir un objeto espacial)
- La implementación de modelos de datos específicos de la aplicación es mucho más fácil (modelo de hidrología, modelo de contaminación, modelo de catastro, ...)
- No propietario: la estructura es transparente para el usuario
- Las operaciones DML basadas en SQL son compatibles con los tipos de datos espaciales.
- Gran soporte para la funcionalidad mejorada de DBMS como replicación, carga masiva, etc.
- Mucho mejor rendimiento que el modelo relacional
- Admite nuevas capacidades de modelado real de objetos (jerarquías de tipos, ...)
Desventajas
- Para no ser demasiado entusiasta, todavía deben considerarse algunas desventajas. No todas las funciones avanzadas de DBMS son compatibles con los tipos de datos espaciales.
3.3 Índices
Los índices proporcionan accesos directos a los datos. Los índices son importantes porque hacen posible un tiempo de respuesta rápido sin el requisito de invertir mucho en recursos del sistema para aumentar la potencia informática. Proporcionan una ruta de acceso inteligente a los datos en comparación con la alternativa de buscar secuencialmente una tabla / archivo para la información buscada. Existe una variedad de índices y el índice que debe elegirse depende del tipo de datos y del tipo de consultas. Por lo tanto, la aplicación del índice correcto requiere experiencia en ambas áreas: dominio de los datos (por ejemplo, se requiere conocimiento en el dominio espacial al almacenar datos espaciales) y relacionados con DBMS (por ejemplo, comprender los índices y cómo DBMS utiliza los índices). Esta lección proporciona un conocimiento fundamental sobre los índices.
El siguiente ejemplo describe el peor de los casos de acceso a datos:
Considere un archivo de 10,000 registros. Las consultas que requieren el procesamiento de todos los registros requerirán que se acceda a todos los 10,000 registros (por ejemplo: Buscar todos los elementos de tipo “E”). Muchos accesos al disco se desperdician si solo unos pocos registros cumplen la condición de búsqueda. Este método de acceso secuencial se denomina búsqueda de exploración de tabla completa, lo que generalmente causa un mal rendimiento. Es el “asesino de rendimiento” para bases de datos más grandes.
Nota: Con frecuencia encontrará el término archivo en esta lección. No se confunda, todo lo que hablamos es aplicable a DBMS. Pero al final del día, todos los datos DBMS se almacenan en una estructura de archivos indexados en un disco.
Un índice es una estructura de datos que permite al DBMS localizar registros particulares en un archivo (= tabla) más rápidamente y, por lo tanto, mejorar la respuesta a las consultas. El archivo consta de un archivo de índice y un archivo de datos. El archivo de índice contiene valores clave ordenados y un puntero al registro de datos.
Con respecto a su definición, un índice: un índice es una estructura secundaria con un patrón específico, que apunta (relaciona) a una estructura primaria (datos).
Existen diferentes estrategias de acceso a datos que pueden implementarse, dependiendo del tipo de datos y especialmente dependiendo de las consultas publicadas.
Heap (random order): adecuados cuando el acceso típico requiere la exploración de todos los registros (datos).
Sorted Files: es más adecuado si los registros deben recuperarse en algún orden, o si solo se necesita un “rango” de registros.
Indexes (Índices): La metodología más sofisticada (en comparación con los métodos anteriores). Se genera una estructura secundaria para optimizar el acceso a los datos. Las estructuras de datos secundarias se organizan a través de árboles o hash. Al igual que los archivos ordenados, aceleran las búsquedas de un subconjunto de registros, en función de los valores en ciertos campos (“clave de búsqueda”). Las actualizaciones son mucho más rápidas que en los archivos ordenados.
Un índice en un archivo acelera las selecciones en los campos clave de búsqueda para el índice. Su objetivo principal es reducir los requisitos de acceso al disco. Cualquier subconjunto de los campos de una relación puede ser la clave de búsqueda de un índice en la relación. Tenga en cuenta que una clave de búsqueda no es lo mismo que una clave. Como recordatorio: una clave es un conjunto mínimo de campos que identifican de forma única un registro en una relación. Un índice contiene una colección de entradas de datos y admite la recuperación eficiente de todas las entradas de datos k * con un valor clave dado k.
3.3.1 Índices agrupados versus no agrupados (Clustered vs. unclustered indexes)
Se ordena un índice agrupado (se ordenan los valores clave). Se mantiene la proximidad de los valores de datos en el archivo.
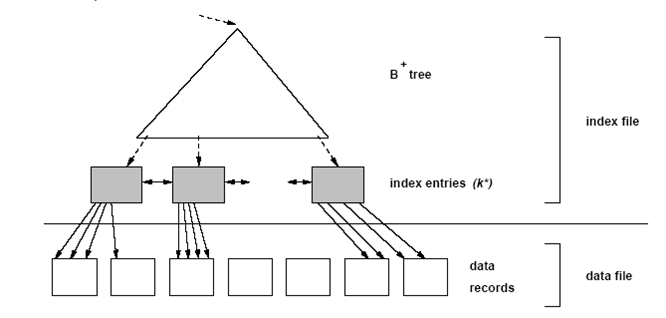
Supongamos que tenemos que admitir selecciones de rango en registros del tipo “X debe estar en el rango entre A y B”.
Si mantenemos un índice en el campo A, podemos consultar el índice una vez para un registro con A = inferior, y luego escanear secuencialmente el archivo de datos desde allí hasta encontrar un registro con el campo A> superior. Esto funciona siempre que el archivo de datos esté ordenado en el campo A (Figura 3.3).
Las búsquedas secuenciales en índices agrupados detectan rápidamente valores cercanos entre sí.
Un índice no agrupado no está ordenado y las entradas de índice están dispersas.
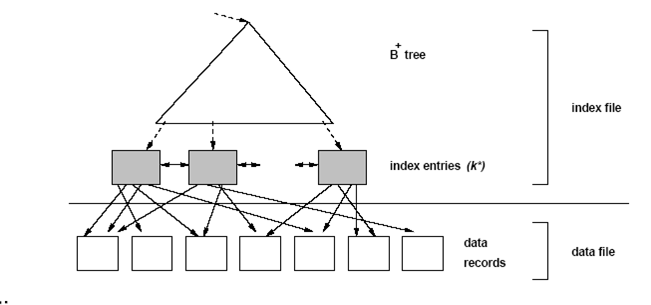
En general, el costo de una selección de rango aumenta enormemente si el índice de A no está agrupado (no está ordenado). En este caso, la proximidad de las entradas de índice no implica proximidad en el archivo de datos. Como antes, podemos consultar el índice para un registro con A = más bajo. Sin embargo, para continuar con el escaneo, tenemos que volver a visitar las entradas de índice que apuntan a datos dispersos por todo el archivo de datos (Figura 3.4).
3.3.2 Índices densos versus dispersos (Dense vs. sparse indexes)
Un índice disperso no se refiere directamente a un solo registro, sino a páginas, donde una página es una pieza distintiva de memoria que generalmente consta de más de un registro. Los índices escasos están utilizando un nivel más alto de organización de datos. Mantienen los requisitos de espacio en disco lo más bajo posible.
Los índices densos, por el contrario, se refieren directamente a los registros. El espacio de almacenamiento de índices densos es mayor debido al mayor nivel de detalle.
Para buscar un registro con el campo A = k en un índice A disperso, nosotros
- Ubique la entrada de índice más grande k ‘* de modo que k’ <= k, luego
- Acceder a la página señalada por k ’*, y
- Escanee esta página (y las páginas siguientes, si es necesario) para buscar registros con <. . , A = k,. . >.
Dado que el archivo de datos está agrupado (es decir, ordenado) en el campo A, tenemos la garantía de encontrar registros coincidentes en su proximidad.
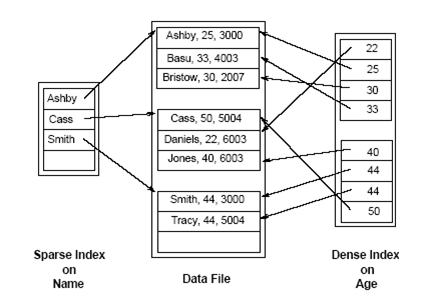
En el ejemplo de la Figura 3.5, en el lado izquierdo se genera un índice disperso (sparse). Verá que las entradas de índice apuntan a páginas (que contienen más de un registro). En el lado derecho, se genera un índice denso en la edad del campo, con punteros a cada registro.
La decisión sobre índices dispersos versus índices densos está relacionada con índices agrupados y no agrupados:
Un índice agrupado tiene más ventajas que la velocidad mejorada para las selecciones de rango presentadas anteriormente. Además, podemos diseñar el índice para que ahorre espacio: para mantener pequeño el tamaño del archivo de índice, mantenemos un índice disperso con solo una entrada de índice k * por página de archivo de datos. La clave k es la clave de búsqueda más pequeña en esa página. Los índices escasos necesitan 2-3 órdenes de magnitud menos espacio que los índices densos. Solo podemos construir un índice disperso con índices agrupados.
3.3.3 Índices de atributos múltiples (Multi-attribute indexes)
Cada una de las técnicas de índice esbozadas hasta ahora se puede aplicar a una combinación de valores de atributo de una manera directa:
- concatenar atributos indexados para formar una clave de índice,
p.ej. -> clave de búsqueda
- definir índice en la tecla de búsqueda
el índice admitirá una búsqueda basada en ambos valores de atributo,
p.ej. . . . WHERE apellido = “Doe” Y nombre = “John”. . .
- posiblemente también admitirá una búsqueda basada en el “prefijo” de valores,
p.ej. . . . WHERE apellido = ‘Doe’. . .
Existen estructuras de índice más sofisticadas que pueden proporcionar soporte para búsquedas simétricas para ambos atributos solos (o, para ser más generales, para todos los subconjuntos de atributos de índices). A menudo se denominan “índices multidimensionales”. Se ha propuesto una gran cantidad de tales índices, especialmente para aplicaciones geométricas.
La indexación convencional no puede respetar la naturaleza multidimensional de los datos. Tomemos por ejemplo datos espaciales. Una consulta para encontrar todos los datos dentro de un área determinada requeriría una búsqueda en:
- todos los registros en el campo X y buscar aquellos registros que están dentro del rango X
- luego revise los registros en el campo Y y obtenga los registros que están dentro del rango Y hasta que se logre el resultado.
No intente realizar esta operación en un conjunto de datos grande (la tabla se escanea completamente dos veces, al menos). El uso de índices convencionales no ayuda a aumentar el rendimiento.
Los índices evitan el tedioso acceso secuencial a los datos. El acceso rápido a datos espaciales cuando se accede por su dominio espacial requiere métodos de indexación espacial. Discutiremos la estructura del índice espacial en la Lección “Indexación espacial”.
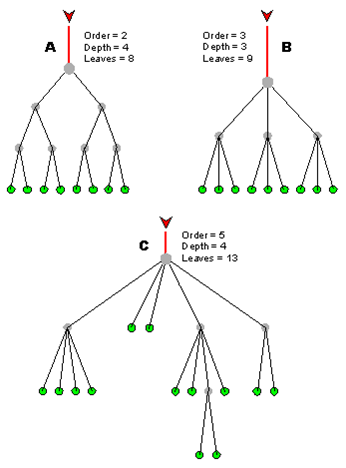
3.4 Índices de árbol
En un árbol, los registros se almacenan en ubicaciones llamadas hojas. Este nombre deriva del hecho de que los registros siempre existen en los puntos finales; No hay nada más allá de ellos. Los puntos de ramificación se llaman nodos. El orden de un árbol es el número de ramas (llamadas hijos) por nodo (Figura 3.6).
3.4.1 Árboles binarios
Un árbol binario es un método para colocar y ubicar archivos (llamados registros o claves) en una base de datos. El algoritmo encuentra datos dividiendo repetidamente la cantidad de registros accesibles en última instancia por la mitad hasta que solo quede uno. En un árbol binario, siempre hay dos hijos por nodo, por lo que el orden es 2.
El número de hojas en un árbol binario es siempre una potencia de 2. El número de operaciones de acceso requeridas para alcanzar el registro deseado se denomina profundidad del árbol (Figura 3.7).
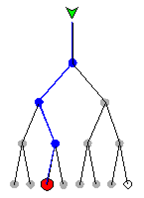
Los árboles binarios son excelentes cuando todos los datos están en la memoria de acceso aleatorio (RAM). El algoritmo de búsqueda es simple, pero no minimiza el número de accesos a la base de datos necesarios para alcanzar el registro deseado. Cuando todo el árbol está contenido en la RAM, que es un medio de lectura rápida y escritura rápida, el número de accesos requeridos es poco preocupante. Pero si algunos o todos los datos están en el disco, que es de lectura lenta, escritura lenta, es ventajoso minimizar el número de accesos (la profundidad del árbol). Algoritmos alternativos como el árbol B logran esto.
Por lo tanto, los árboles binarios son buenos para pequeños conjuntos de datos. Para un gran conjunto de datos, un árbol binario no es una buena opción, ya que la profundidad del árbol se agrandará, eliminando muchos beneficios de rendimiento.
3.4.2 Índice B-Tree
En contraste con un árbol binario, un árbol B no solo tiene 2 hijos, sino 3 o más hijos. El número de hijos de un nodo se llama el orden del árbol. La cantidad de veces que se debe acceder a un medio para ubicar un registro deseado (es decir, la cantidad de niveles) se denomina profundidad del árbol (Figura 3.8).
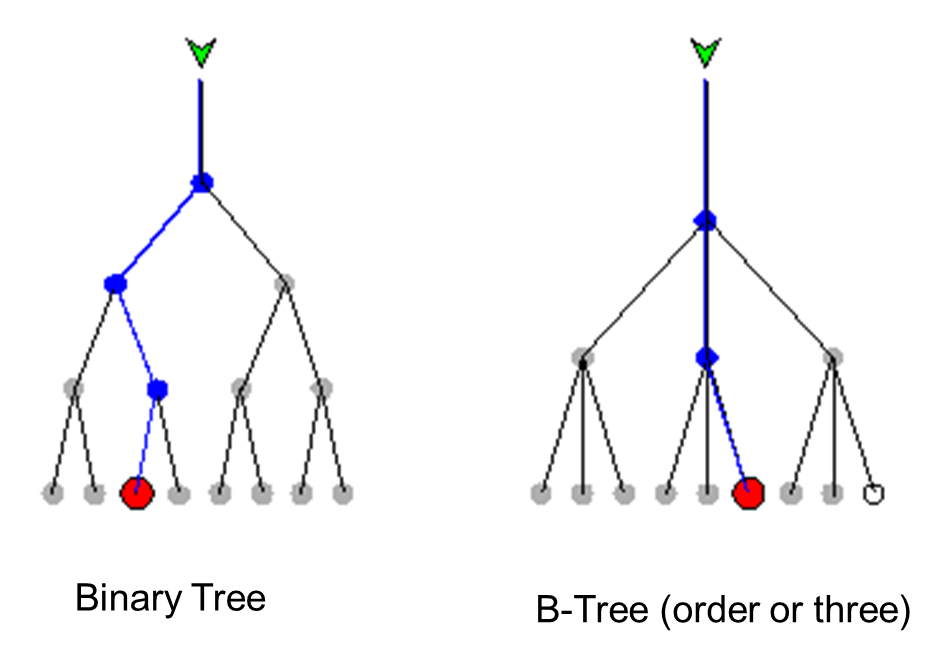
En resumen, el algoritmo del árbol B minimiza el número de veces de acceso para localizar un registro deseado y, por lo tanto, optimiza el acceso a grandes conjuntos de datos y acelera el proceso de búsqueda. En un árbol B de una base de datos grande, puede haber miles, millones o miles de millones de registros. No todas las hojas necesariamente contienen un registro, pero al menos la mitad de ellas sí.
Se prefieren los árboles B cuando los puntos de decisión, llamados nodos, están en el disco duro en lugar de en la memoria de acceso aleatorio (RAM). Se necesita miles de veces más tiempo para acceder a un elemento de datos desde el disco duro en comparación con el acceso desde la RAM, porque una unidad de disco tiene partes mecánicas, lo que hace que las operaciones de lectura y escritura sean mucho más lentas que las operaciones de lectura y escritura desde / hacia medios electrónicos.
El árbol B generalmente permite ubicar un registro deseado más rápido que los árboles binarios (menos pases de acceso), suponiendo que todos los demás parámetros del sistema sean idénticos. Pero el proceso de decisión en cada nodo es más complicado en un árbol B que en un árbol binario. Por lo tanto, debe realizarse una compensación entre el alto orden de los árboles y la complejidad de la gestión de un árbol. La gestión de árboles se calcula típicamente en RAM, por lo que se ejecuta rápidamente.
La diferencia en profundidad entre los esquemas de árbol binario y árbol B es mayor en una base de datos grande que en el ejemplo simplista ilustrado aquí, porque los árboles B del mundo real son de orden superior (32, 64, 128 o más). Dependiendo del número de registros en la base de datos, la profundidad de un árbol B puede cambiar, y a menudo cambia. Agregar un número suficientemente grande de registros aumentará la profundidad de un árbol B; eliminar un número suficientemente grande de registros disminuirá la profundidad. Esto asegura que el árbol B funcione de manera óptima para la cantidad de registros que contiene.
La gestión de B-Tree generalmente se realiza automáticamente por el DMBS. Los árboles B proporcionan una estructura de índice equilibrada que es resistente al sesgo de datos y se adapta automáticamente a las inserciones y eliminaciones dinámicas. Para acceder a los detalles, consulte siempre la documentación de DBMS.
Un árbol B está diseñado para ramificarse en este gran número de direcciones y para contener muchas claves en cada nodo, de modo que la profundidad del árbol sea relativamente pequeña. Por lo tanto, solo se debe leer un pequeño número de nodos de un disco para recuperar un elemento. El objetivo es obtener un acceso rápido a los datos, y con las unidades de disco esto significa leer una cantidad muy pequeña de registros. La reducción de las operaciones de entrada / salida de disco (E / S de disco) suele ser un método de ajuste muy eficiente. Piense en esto: el disco es principalmente el único dispositivo mecánico en una computadora (independientemente de lo sofisticado que sea). La mecánica se traduce directamente en lento.
Tenga en cuenta que un gran tamaño de nodo (con muchas claves en el nodo) también se ajusta al hecho de que, con una unidad de disco, generalmente se puede leer una buena cantidad de datos a la vez.
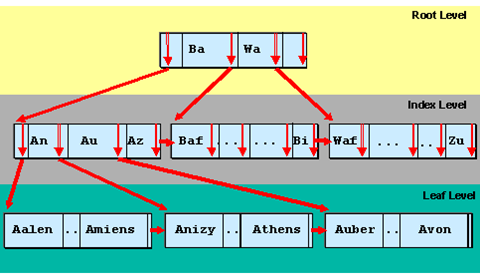
El índice es eficiente si está equilibrado, de modo que finalmente se debe escanear un número similar de registros de datos para encontrar datos específicos. El nivel más bajo (hojas) apunta a los datos. Observe las pequeñas cajas al costado de cada personaje. Indican la clave de índice, apuntando entre nodos y finalmente a las hojas (datos; Figura 3.9).
3.5 Índices basados en hash
Un índice hash es bueno para las selecciones de igualdad. Básicamente es una colección de cubos. Un depósito es una página principal más cero o más páginas de desbordamiento. Los cubos contienen entradas de datos.
Función de hash h: h (r) = depósito al que pertenece (entrada de datos para) el registro r. h mira los campos clave de búsqueda de r.
La función hash identifica el depósito de la clave de búsqueda. A través del depósito, se identifica el registro de la clave de búsqueda

Para buscar valores de la clave de búsqueda, se utiliza la función hash, que identifica las páginas para buscar el depósito específico donde residen los datos reales. La función hash traduce la clave de búsqueda a una clave de búsqueda que apunta a los cubos. En la Figura 3.10, el resultado de la función hash es
- 0 si la búsqueda en la edad del campo clave es “edad entre 20 y 30”,
- 1 si la búsqueda en el campo clave es “edad entre 21 y 40”,
etc.
Para buscar en otro campo (clave que no sea de búsqueda), será necesario escanear el archivo, lo que generalmente resulta en una operación de escaneo de tabla completa.