6 Big Data Data Science e IA
6.1 Big Data
De acuerdo con Pascual (2017), citado por Pantoja (2020); se puede hablar de Big Data cuando se cuenta con varios Terabytes de información, que pueden o no estar organizados u ordenados. Ahora bien, para obtener información relevante y de calidad a partir de tal cantidad de datos se requiere aplicar una serie de técnicas y dominar conocimientos que hacen parte de lo que se conoce como Data Science (Ciencia de Datos).
6.2 Data Science o Ciencia de Datos
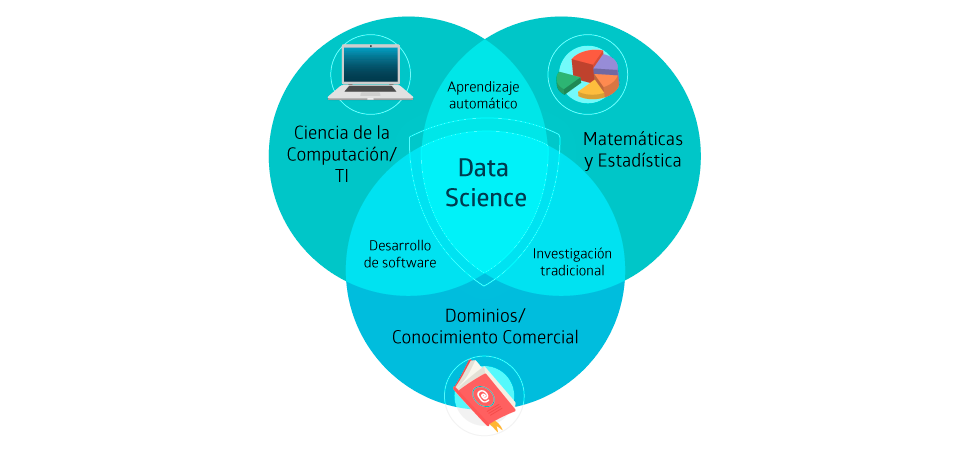
Almacenar y procesar una gran cantidad de datos e información requiere de un conjunto de herramientas tecnológicas y conocimientos matemáticos, estadísticos y de inteligencia de negocio. Ahí aparece entonces el concepto de Data Science que cuenta con diferentes técnicas y modelos, entre los que se puede mencionar: analítica descriptiva, estadística, data mining y el machine learning (Pascual (2017); citado por Pantoja (2020)). Las relaciones entre estos conceptos mencionados los podemos ver en la Figura 6.1.
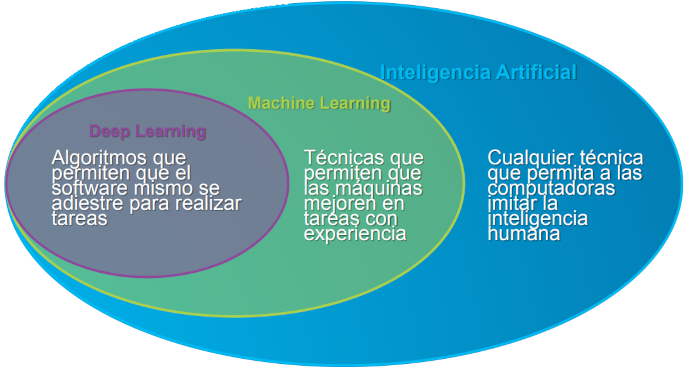
A la vez, la ciencia de datos se relaciona de manera paralela con otro concepto incluso más amplio que es la Inteligencia Artificial, tal como se observa en la Figura 6.2.
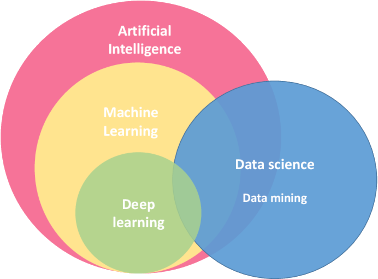
A continuación veremos una serie de conceptos estrechamente relacionados tanto a la Data Science como a la Inteligencia artificial, ampliando así lo que estamos observando en la Figura 6.2
6.3 Data Mining (Minería de Datos)
Según citan Matos, Chalmeta, y Coltell (2006) y Pantoja (2020); la definición formal de data mining o minería de datos es, “el conjunto de técnicas y herramientas aplicadas al proceso no trivial de extraer y presentar conocimiento implícito, previamente desconocido, potencialmente útil y humanamente comprensible, a partir de grandes conjuntos de datos, con objeto de predecir de forma automatizada tendencias y comportamientos previamente desconocidos”.
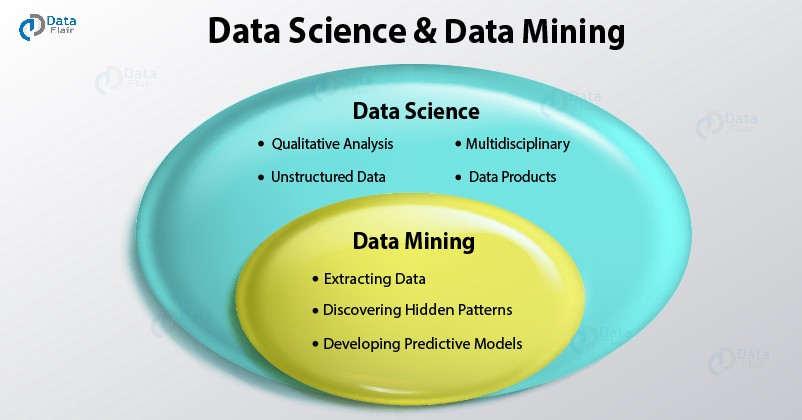
La minería de datos hace parte de la ciencia de datos, y es una herramienta para explorar, extraer y exponer información útil, que de otro modo sería difícil reconocer. Tal como se puede ver en la siguiente Figura 6.3, el Data Mining hace parte de la Ciencia de Datos, y permite la Extracción de Datos, el Descubrimiento de Patrones Ocultos, y el desarrollo de modelos predictivos mediante distintas técnicas.
Según cita Vallejo Ballesteros, Guevara Iñiguez, y Medina Velasco (2018) y también Pantoja (2020), la minería de datos trata de aprovechar la gran cantidad información a la que se puede acceder hoy en día, y la potencia de los nuevos computadores para realizar operaciones de análisis sobre esos datos. El Data Mining permite encontrar información escondida en los datos, mediante un proceso de identificación de información relevante con el objetivo de descubrir patrones y tendencias.
6.4 Técnicas de Data Mining
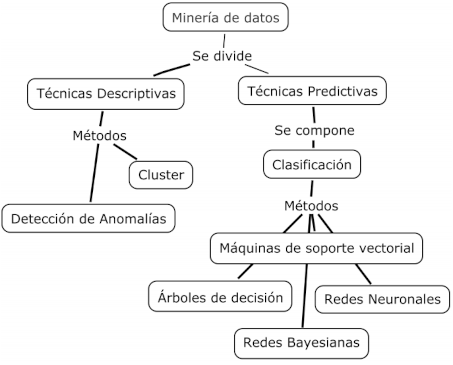
Según Llordachs Marqués (2016) , citado por Pantoja (2020) en el ámbito de la investigación las técnicas de Data Mining pueden ayudar a los científicos a clasificar y segmentar datos, además de formar hipótesis, y se puede clasificar en dos tipos:
- Métodos descriptivos: Un método descriptivo es, por ejemplo, el clustering, que busca descubrir reglas de asociación y patrones secuenciales. Y son utilizados para ver qué productos suelen adquirirse conjuntamente en el supermercado, entre otros múltiples propósitos.
- Métodos predictivos: “Usan algunas variables para predecir valores futuros o desconocidos de otras variables. Algunos métodos de este tipo son los siguientes: clasificación, regresión y detección de la desviación. En medicina, por ejemplo, los métodos predictivos pueden emplearse en tareas como clasificar tumores en benignos o malignos.” ( Llordachs Marqués (2016) ).
Un esquema que representa estos dos métodos y sus ramificaciones se muestra en la Figura 6.4:
Según Llordachs Marqués (2016) , citado por Pantoja (2020), el proceso de data mining tiene su propio estándar, el CRISP-DM (Cross-Industry Standard Process for Data Mining), que establece seis pasos a seguir para aplicar el proceso:
- Entender el área en el que se quiere usar data mining para definir con claridad el problema.
- Recolectar y entender los datos.
- Preparar los datos: hacer tablas con los campos requeridos, eliminar datos innecesarios.
- Seleccionar la técnica de modelado: construcción del modelo y puesta a prueba del modelo.
- Evaluar de los resultados y revisión del proceso.
- Desplegar e implementar un proceso de Data Mining repetible.
De acuerdo a la cita de Ramos Díaz (2016) y Pantoja (2020), algunas de las principales técnicas de minería de datos basadas en el descubrimiento de información entre los datos son:
- Reglas de asociación: Se usan para descubrir fenómenos en común o relaciones que ocurren en un conjunto de datos. De acuerdo con las reglas de asociación se pueden usar en contextos como el análisis Web, marketing, detección de intrusos, producción continua, bioinformática, entre otros.
- Reglas de clasificación: Basado en el descubrimiento de reglas que permiten “particionar” los datos en conjuntos disjuntos.
- Redes neuronales: Inspirado en la forma en que funciona el sistema nervioso, se construye un sistema de aprendizaje y procesamiento automático en el que un sistema de neuronas compone una red que colaboran entre ellas para producir el resultado de salida. Según González-Ruiz et al. (2015), este tipo de análisis es comúnmente utilizado en las ciencias sociales y tecnológicas: manufactura, biología, finanzas, previsión del tiempo, análisis de tendencias y patrones, entre otros.
6.5 Inteligencia Artificial
De acuerdo con Itelligent (2018), citado por Pantoja (2020), la Inteligencia Artificial (IA) tiene como objetivo que a través de la computación y el Machine Learning se puedan realizar determinadas operaciones que se consideran propias de la inteligencia humana, llegando incluso a gestionar nuevas situaciones sin la intervención del ser humano. Según Abarca-Alvarez, Campos-Sánchez, y Reinoso-Bellido (2017) la IA se usa para resolver problemas de predicción, clasificación y reconocimiento de patrones. Los temas que abarca la IA de manera directa son el Aprendizaje Automático y el Aprendizaje Profundo, tal como se observa en la Figura 6.5
6.5.1 Machine Learning
El Machine Learning (Aprendizaje Automático), es un concepto relacionado con el Data Mining, aunque tiene sus diferencias en cuanto a origen, aplicación y objetivos. El Machine Learning tiene como objetivo desarrollar modelos computacionales capaces de inducir conocimiento a partir de experiencia previa [González-Ruiz et al. (2015) ; citado Pantoja (2020). Es decir, se entrena los modelos para intentar predecir algún fenómeno particular (Pedamkar 2018). Técnicamente el Machine Learning hace parte de la inteligencia artificial (la cual busca que un programa determinado actúe, se adapte y razone de la manera más parecida a un ser humano), y se ocupa del aspecto de aprender de manera automática para tomar decisiones acertadas (o por lo menos cercanas a las acertadas).
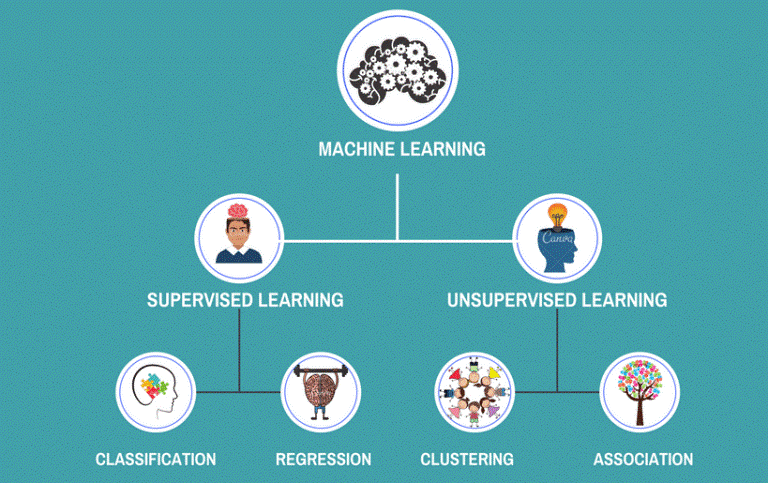
Los métodos que se usan en Machine Learning se dividen en dos principales clases, supervisados y no supervisados, tal como se muestra en la Figura 6.6
6.6 Deep Learning
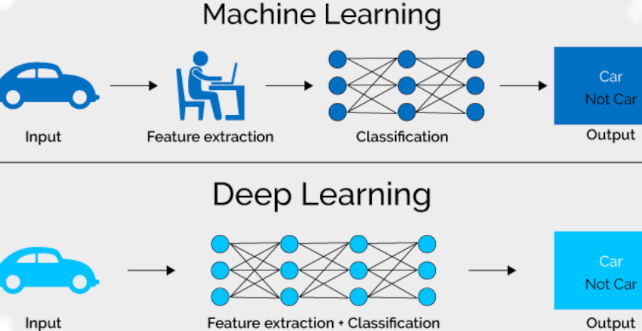
Se trata de una técnica de Machine Learning no supervisada, que usa una red neuronal artificial compuesta por varias capas. Eso le permite obtener un alto grado de éxito y permite ahorrar costos de supervisión humana en grandes conjuntos de datos. Sin embargo, puede consumir más recursos computacionales y tiempo, García Monsálvez (2017) citado por Pantoja (2020)). Según el portal Bismart (Gorini s. f.), “Mientras que el Machine Learning trabaja con algoritmos de regresión o con árboles de decisión, el Deep Learning usa redes neuronales que funcionan de forma muy parecida a las conexiones neuronales biológicas de nuestro cerebro”. Las diferencias se pueden ver de manera más clara en la Figura 6.7:
En resumen, como lo expresa Cabana (2019) , citado por Pantoja (2020), “el Deep Learning es una nueva rama del Machine Learning, que a su vez es una rama de la Inteligencia Artificial. El Big Data es un conjunto de tecnologías independientes que no tienen necesariamente que estar relacionadas con la Inteligencia Artificial y que obedecen más al concepto de gestión de multitud de datos. Entonces, ser un científico de datos (data scientist), requiere tener un dominio medio-alto de inteligencia artificial, machine learning, deep learning y big data”.
6.7 Data Science y SIG
La creciente disponibilidad de información espacial ha posibilitado la aplicación de las técnicas de Inteligencia Artificial y Machine Learning al campo de los Sistemas de Información de Geográfica (SIG). Al respecto Abarca-Alvarez, Campos-Sánchez, y Reinoso-Bellido (2017), citado por Pantoja (2020), recogen experiencias de este tipo en temas de planificación urbana y territorial, así como también geografía humana y urbana que se han tratado con aprendizaje no supervisado, mapas auto organizados y construcción mediante aprendizaje supervisado con árboles de decisión. Como resultado de su investigación advierte que la integración completa entre la creación de Mapas Auto-organizados (SOM) y SIG todavía no se ha implementado de manera efectiva para que se pueda trabajar de manera directa y amigable en los principales programas SIG (Abarca-Alvarez, Campos-Sánchez, y Reinoso-Bellido 2017).
A pesar de ello, de acuerdo a la recopilación de literatura y su propia experiencia durante su investigación, Abarca-Alvarez, Campos-Sánchez, y Reinoso-Bellido (2017) concluyen que la metodología SOM tiene varias utilidades como lo es por ejemplo: realizar análisis exploratorio, comprender los patrones de distribución espacial, analizar complejos conjuntos de datos geográfico-demográficos; inferir consideraciones espaciales a partir de los grupos taxonométricos; codificar las clasificaciones resultantes en un SIG consiguiéndose hacerlos más accesibles y comprensibles; etiquetar la realidad geográfica sin tener que nombrar tales categorías, entre otras.
Abarca-Alvarez, Campos-Sánchez, y Reinoso-Bellido (2017) también evaluaron la metodología basada en árboles de decisión a partir de una clasificación SOM y concluyeron que son útiles para: atribuir patrones de comportamiento que pueden ser muy complejos; predecir comportamientos de variables que presentan cierto coste o dificultad de evaluación, como son las variables demográficas o sociales, a partir de otras variables con menor complejidad y coste de evaluación, como las variables residenciales; identificar variables que se relacionan de forma significativa y su peso o tamaño del efecto en la realidad estudiada. Actualmente algunos programas para Sistemas de Información Geográfica están incorporando nuevas herramientas que permiten aplicar los conceptos de la ciencia de datos y especialmente el Machine Learning al análisis espacial. Como el caso del software licenciado ArcGIS, que de acuerdo con Ruiz y Galvis (2018), citado por Pantoja (2020), incluye funcionalidades como las siguientes:
- Clustering: Agrupación de observaciones basadas en similitudes de valores o ubicaciones: agrupamiento multivariado, agrupamiento basado en densidad, segmentación de imágenes y análisis Hot Spot.
- Clasificación: Decidir a qué categoría se debe asignar un objeto en función de los datos: Hallar ubicaciones adecuadas, identificar la mejor ruta existente entre ubicaciones y cálculos zonales.
- Predicción: Usar lo conocido para estimar lo desconocido, modelos determinísticos, interpolación de áreas y mapas de probabilidad.