6 Componentes y Funciones de un SIG
6.1 Introducción
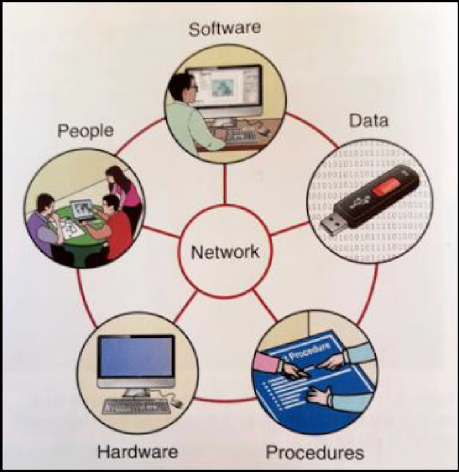
Hay diferentes enfoques para definir los componentes mayores de un SIG. Longley et al. (2015) (Figura 6.1) lista seis componentes de un SIG: redes, equipos, aplicativos, datos, procedimientos y personal. Dependiendo del punto de vista, ciertas partes pueden ser consideradas más importantes que otras. Por ejemplo, un vendedor de aplicativos se enfocará en la funcionalidad del SIG por este ofrecido y tratará de convencerle que un “Producto X” es el mejor de los disponibles en el mercado. Un docente de SIG le dirá que cualquier aplicativo será útil si cuenta con el personal calificado para usarlo. El vendedor de equipos, de otro lado, tratará de venderle el equipo más reciente y veloz del mercado.
Al formular un proyecto con el uso de SIG, es importante mirar dentro del flujo de trabajo cuáles de los componentes son más relevantes y dentro de estos, cuáles funciones se espera cumplan. Ello garantizará seleccionar los componentes claves para las funciones deseadas.
En esta lección nos enfocaremos en todos los componentes que son necesarios para diseñar, crear y poner en funcionamiento un SIG.
6.2 Componentes de un SIG
Un SIG moderno ha sido considerado como una red que interconecta aplicativos, equipos, datos, procedimientos y personal (Figura 6.1). La mayoría de nosotros ha tenido alguna interacción con alguno de estos componentes en nuestra cotidianidad, bien sea instalando equipos o aplicativos, compartiendo datos por la Internet.
6.2.1 Redes
Una red es una forma de comunicación entre diferentes sistemas, que permite una rápida comunicación e intercambio de información digital. Las redes son indispensables para los SIG actuales haciendo de los SIG aislados una rareza. Cuando se habla de redes en la mayoría de los casos se hace referencia a la Internet. Internet fue originalmente diseñada como una red para conectar computadores. Su transformación ha sido rápida hacia una herramienta que la sociedad usa ampliamente para intercambiar información vía correo electrónico, transacciones bancarias o transferencia de grandes bases de datos. Las raíces de la Internet se encuentran en el proyecto del departamento de defensa de los Estados Unidos llamado Advanced Research Project Agency Network (ARPANET) en 1972. Los orígenes de la World Wide Web se atribuyen a Sir Tim Berners-Lee, científico del CERN, quien en 1980 desarrolló la capacidad del hipertexto para uso en comunicación entre varios computadores, diferentes sistemas operativos, lenguajes de programación y culturas sub corporativas.
La aceptación de las tecnologías Web fue mucho más rápida que otras innovaciones como la radio, teléfono o TV. Su uso se ha incrementado hasta reportar en marzo del 2022, cerca de 5382 millones de usuarios en el mundo entero, lo que equivale a 67.8% de la población mundial (Miniwatts Marketing Group, 2022).
La adopción de la Internet ha beneficiado en múltiples formas a los usuarios de los SIG. Entre los varios beneficios se tiene:
- Diseminación de información
- Venta de bienes y servicios
- Beneficios directos por medio de los servicios de suscripción
- Participación del público a nivel local, regional y nacional
- Aparición de redes de temas geográficos y geoportales
- Desarrollo de servicios basados en la localización
El mapeo con SIG fue introducido en la Web a mediados de los años 1990 a la manera de servicio de mapas en línea. Hoy hay miles de servidores de mapas en la Internet que ofrecen cientos de millones de mapas cada día.
6.2.2 Equipos (Hardware)
Los equipos o el hardware son considerados el aspecto más técnico del SIG. Desde una perspectiva organizacional, el hardware es necesario para facilitar a los otros componentes como los aplicativos (software) y las redes operar adecuadamente. La imagen a continuación (Figura 6.2), muestra una granja de servidores web para procesamiento de datos en la nube.

Debido al rápido progreso tecnológico y a las constantes reducciones de precio, el hardware casi nunca es un problema. Las aplicaciones SIG funcionan en casi todos los ordenadores, portátiles o smartphones. Gracias a la disponibilidad generalizada del acceso a Internet y a la enorme infraestructura de la nube, los requisitos de hardware están disminuyendo. La misma tendencia se observa para la capacidad de almacenamiento.
La variedad de hardware conocido equipado con sensores que producen datos espaciales, como el Sistema Global de Navegación por Satélite (GNSS, siglas en inglés), Bluetooth o la Comunicación de Campo Cercano (NFC, siglas en inglés), no deja de crecer. Estos sensores se utilizan para el posicionamiento y la navegación, así como para la navegación en interiores, y pueden combinarse para crear redes de sensores que permitan la adquisición de datos y la comunicación en tiempo real. El desarrollo de la tecnología de Internet, posicionamiento y aplicaciones ha transformado casi todos los dispositivos electrónicos e interconectados en partes del hardware de los SIG. Para más información, consulte este artículo sobre el hardware de las estaciones de trabajo SIG en GISGeography.
Piense en su vida cotidiana y en cuántos, de dispositivos utiliza, que necesitan o utilizan información espacial. Piense en el posicionamiento espacial absoluto y en la conexión espacial relativa.
6.2.3 Aplicativos (Software)
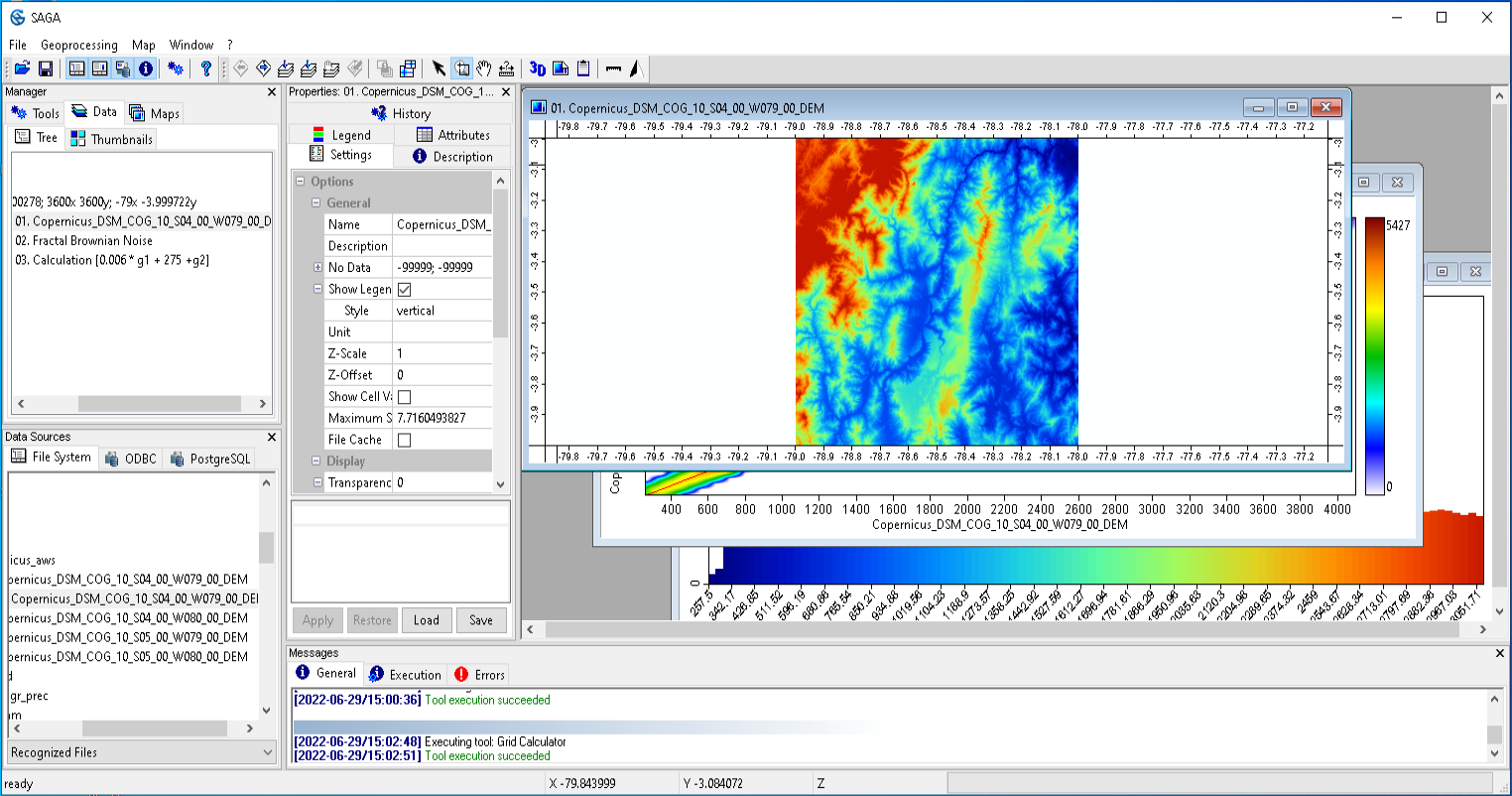
El software son instrucciones que indican a un ordenador lo que debe hacer. El software comprende todo el conjunto de programas, procedimientos y rutinas asociados al funcionamiento de un sistema informático (Britannica 2022). Un aplicativo es un software que ayuda al usuario final a realizar tareas específicas, como por ejemplo: investigar, tomar notas, programar una alarma, diseñar gráficos o llevar un registro de cuentas (Braden 1996). A continuación, en la Figura 6.3 se muestra la interfaz gráfica del software SAGA-GIS.
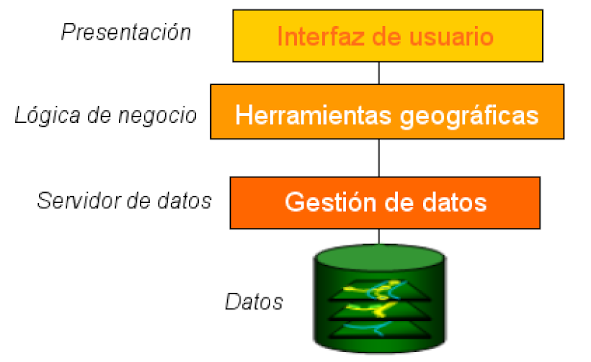
Antes de empezar con los diferentes tipos de sistemas vamos a explorar las partes clave de la arquitectura del software SIG. Diferenciamos tres tipos de componentes:
- La interfaz de usuario: Un grupo de interfaces mediante menús o botones que implementan las tareas principales del sistema (localizar datos, crear mapas, geo codificar direcciones, etc.)
- Herramientas geográficas/analíticas: Los procesos principales que constituyen la mayoría de las funcionalidades y posibilidades del software.
- Sistemas de Gestión de Datos: El nivel más bajo, componentes que permiten el almacenaje y gestionan el acceso a los datos geográficos.
El software SIG proporciona al ordenador las instrucciones para realizar las tareas que debe desarrollar, facilitando el proceso de adquisición de datos, procesamiento y transferencia a la memoria del sistema para su posterior procesamiento. Cuando hablamos de software SIG nos referimos al sistema informático que permite editar, integrar, almacenar, analizar, compartir y visualizar información georreferenciada. Normalmente, el software SIG incluye funciones que permiten llevar a cabo todas estas operaciones. No obstante, es imprescindible que los datos estén en formato digital compatible con nuestro software, por lo que algunas veces el proceso puede incluir la transformación de los datos de un formato a otro para hacerlos compatibles con los formatos específicos que usa el software SIG que estemos utilizando. El proceso puede conllevar también una transformación geométrica para presentar los datos en el mismo sistema de coordenadas. El proceso de georreferenciación implica la transformación algebraica de los puntos de coordenadas X, Y (y a veces Z) de un sistema de referencia a otro. Como consecuencia, debemos tener en cuenta que en todo software y en su proceso relacional existen tres etapas básicas (véase la Figura 6.5): entrada de datos (input), procesamiento (process) y salida de información (output).

Todos estos procesamientos pueden llevarse a cabo gracias a que muchos SIG tienen un conjunto de funciones de análisis espacial y modelado que permiten sintetizar nuevos datos espaciales, por combinación de dos o más conjuntos de datos. También nos permiten cuestionar los datos que vemos en la pantalla. Algunos tienen la capacidad de enlazarse a programas externos o motores de modelado. Estos programas generan datos espaciales utilizando algoritmos que pueden ser extensiones del propio SIG -localizadas en un software externo- y que se enlazan a través del sistema operativo de la plataforma en la que está el software SIG. La elección final del software SIG dependerá de para qué y cómo queramos usarlo y qué recursos tengamos para llevar adelante un proyecto. Lo que determina cuál es la tecnología más adecuada para cada aplicación es la calidad, el volumen de producción, el tamaño y el coste que podemos asumir para la compra del software.
Existe gran diversidad de software SIG que puede clasificarse según diferentes aspectos. La elección del software más apropiado para un proyecto o una organización dependerá de varios factores, por ejemplo: los objetivos, los requerimientos en funcionalidades del SIG, los recursos disponibles, la duración del proyecto, los conocimientos previos de los técnicos, la tecnología accesible, etc.
Basándose en sus funcionalidades se pueden clasificar los principales paquetes de software en grupos:
- SIG de escritorio
- SIG web
- SIG móviles
Esta clasificación se basa en software SIG genéricos, y excluye productos como, por ejemplo, atlas, sistemas de mapeo simple, sistemas de procesado de imágenes, o extensiones espaciales de sistemas de gestión de bases de datos. A continuación, se presenta una breve reseña de cada uno de estos:
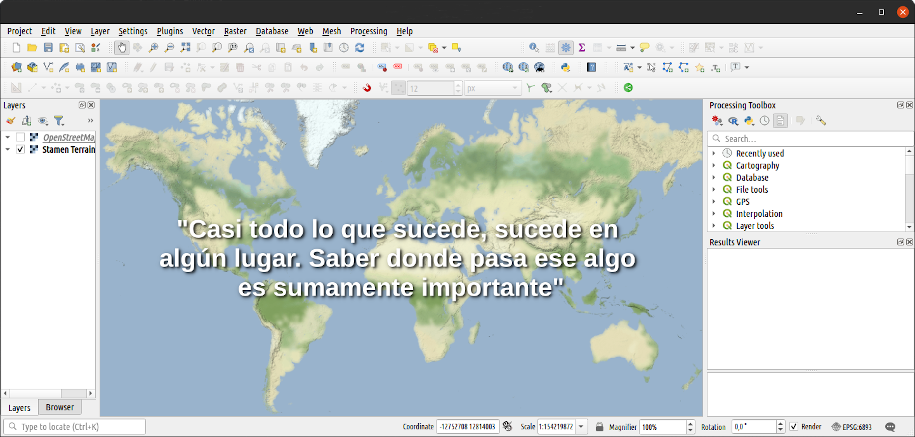
- Los SIG de escritorio (o desktop) son la base de la mayoría de las aplicaciones, y la categoría de software más ampliamente utilizada. El origen de este tipo de software es el ordenador personal. Los SIG de escritorio se ejecutan en el mismo PC/laptop y ofrecen un gran número de herramientas para gran variedad de usuarios en diversidad de campos. Los precios de este tipo de SIG pueden variar dependiendo de su origen, pero por lo general pueden alcanzar hasta unos USD 30.000 por licencia. Durante los últimos años el software SIG de escritorio ha dominado, pero cada vez son más populares los aplicativos activables desde la web y con acceso a una infinidad de datos en servidores disponibles desde cualquier lugar. En la Figura 6.6 se muestra un ejemplo de software de escritorio.
- Los SIG web son productos localizados en un servidor al que acceden los usuarios a través de una red (en este caso el software no está instalado en el PC/laptop). Los SIG web tienen una interfaz de usuario que ofrece funcionalidades de consulta y análisis espacial. Los productos de servidores SIG tienen el potencial para el mayor número de usuarios y el menor coste por usuario, aunque las tareas ejecutadas generalmente son más simples. Es una herramienta muy utilizada en entornos corporativos. En la actualidad, en Internet existen diferentes posibilidades para ejecutar operaciones con información geográfica, como: generar mapas, calcular rutas óptimas, visualizar datos específicos, o hacer análisis basados en criterios seleccionados por el usuario, por ejemplo, de disponibilidad en la compra de inmuebles. En la Figura 6.7 se muestra un ejemplo de software de escritorio
- Los SIG móviles son sistemas ligeros diseñados para su uso en dispositivos móviles principalmente concebidos para trabajo de campo. El desarrollo de este tipo de software ha sido estimulado por los avances en el diseño de hardware, minimizando el peso y el volumen de los dispositivos, las tecnologías GPS y las conexiones a través de redes inalámbricas. Actualmente los SIG móviles ofrecen un gran número de funcionalidades similares a los SIG de escritorio de hace unos años (visualización, consulta, edición, y análisis simples). En la Figura 6.8 se muestra un ejemplo de software de escritorio
Adicionalmente, existen otros tipos de software que incorporan algunas de las funcionalidades de los SIG, por ejemplo:
- Teledetección: ERDAS IMAGINE, ENVI
- CAD (ComputerAidedDesign): Bentley Microstation, AutoCAD
- DBMS (DatabaseManagementSystems): Oracle Spatial, PostGIS (PostgreSQL)
Al comparar el software SIG de escritorio con los SIG web (de servidor) se observa que en el PC los clientes tienen más funcionalidades disponibles y aplicaciones de mayor tamaño. En contraste, los SIG web necesitan servidores potentes que ofrezcan capacidades analíticas extensas, por ejemplo: la geocodificación, la creación de rutas óptimas, la generación de mapas y el análisis espacial. Los SIG de escritorio utilizan los estándares del Sistema Operativo del PC/laptop, en cambio los SIG web pueden usar plataformas Web-Browser (Mozilla Firefox, GoogleChrome, etc.) para desplegar la interfaz de visualización de usuario. En las implementaciones de SIG de escritorio las LAN (Local Area Networks) y las WLAN (Wireless Local Area Networks) tienden a utilizarse para la comunicación cliente-servidor. Los SIG de red se aprovechan de las capacidades y las ventajas de Internet como red informática mundial.
Un punto intermedio entre estos dos productos lo constituyen los geovisores y/o portales de datos. Muchos de estos permiten acceder a datos que sólo reposan en los servidores de las instituciones, pero permiten realizar operaciones básicas de consulta o en algunos casos la descarga de un gran número de datos por área de interés. Este tipo de tecnologías abundan en la web gracias a las políticas de acceso a la información recientemente adoptada por varios países de la región. La Figura 6.9 muestra el visor web de Global Forest Watch. Otros buenos ejemplos también pueden ser consultados en los siguientes sitios:
- Áreas protegidas a nivel global
- Deforestación e incendios a nivel global
- Portal de datos geográficos del Perú
- Instituto Geográfico Militar del Ecuador
Según el acceso al código fuente del software (las líneas de texto escritas en un lenguaje de programación que los desarrolladores de software entienden, y que da lugar a los programas), este puede ser de código abierto (libre) o de código cerrado.
Software libre o de código abierto (en inglés open source software): Este tipo de licencia suele permitir su uso, copia, estudio, modificación y redistribución. Por lo que los desarrolladores pueden adaptar el código del programa a sus necesidades específicas. Este tipo de software suele estar disponible de forma gratuita a través de Internet, pero a veces también puede ser comercializado.
Software propietario o de código cerrado: El código fuente del software no es público, sino que está protegido por leyes de propiedad intelectual por lo que su distribución es considerada un delito.
El software también puede diferenciarse por su licencia de distribución (comercialización) o por los derechos que cada autor se reserva de la obra (libre con o sin protección heredada, semilibre, o no libre). Según los diferentes tipos de licencia de distribución, principalmente se distinguen el freeware y el shareware.
Freeware: se distribuye libremente, de forma gratuita. Su licencia permite su uso y distribución, pero no la alteración de su código.
Shareware: el usuario puede hacer uso libremente del software, pero su uso está limitado en tiempo o características. Se utiliza principalmente para evaluar o hacer demostraciones de los programas.
Los objetivos de las liberaciones de software son diversos. Principalmente se hacen versiones de demostración para captar nuevos usuarios del programa que puedan estar interesados en pagar para obtener versiones completas o con versiones obsoletas de un programa. También se usan estos tipos de licencia para programas que no se considera que puedan reportar beneficios económicos, o por el placer de ofrecer alternativas gratuitas. Contrariamente a lo que normalmente se cree, el software libre no necesariamente es freeware (esta confusión proviene de la traducción del término free, que puede ser gratis o libre). En nuestros proyectos de SIG será fundamental que tengamos en cuenta los aspectos del software comentados anteriormente e identificar la idoneidad de nuestro software para los objetivos propuestos.
Algunos ejemplos de software comerciales desarrollados por compañías líderes incluyen Autodesk AutoCAD Map, ESRI ArcGIS, and Intergraph GeoMedia. La ventaja de invertir en este tipo de software es que han sido desarrollados por profesionales, sus funciones han sido rigurosamente evaluadas y verificadas y permiten cubrir un rango amplio de funciones. Sin embargo, hay también una creciente y significativa comunidad de usuarios de software de código abierto y libre. Ejemplos de estos incluye Quantum GIS (QGIS) y GRASS GIS entre muchos otros.
Revisa los siguientes artículos en GisGeography para conocer software SIG comercial y libre que existen hoy día:
- Clasificación de los 30 Mejores aplicaciones de software GIS
- 13 Opciones de software libre GIS: Mapea el mundo con código abierto
Reconociendo que existen diferentes clases de usuarios de SIG y que sus requerimientos pueden llegar a ser muy diferentes, las tendencias actuales han llevado a la evolución de familias de productos SIG. Estas son colecciones integradas de productos SIG. Los principales distribuidores de software SIG ofrecen un completo rango de paquetes de software a través de Internet a profesionales del SIG para resolver las necesidades de la diversa comunidad SIG. Además, un gran número de distribuidores han desarrollado tecnologías que satisfacen las funcionalidades requeridas en las tareas de gestión de Bases de Datos, de forma que son capaces de almacenar y procesar información geográfica de forma efectiva.
Debemos tener en cuenta que, en realidad, el software SIG se está desarrollando rápidamente y que el mercado del SIG es muy dinámico. También es bastante difícil obtener información precisa del número de usuarios de los diferentes tipos de sistemas de software.
6.2.4 Datos

Los datos son una colección de hechos crudos, los cuales en conjunto y con un propósito determinado se convierten en información. Por ejemplo, los GPS suministran coordenadas y estas son solo datos a menos que representen un objeto o lugar en el cual estamos interesados. Los datos crudos pueden ser complejos de leer y analizar. De allí que sea necesario organizarlos con la ayuda de una base de datos. Una base de datos es un conjunto de datos que tiene una estructura regular y que está organizada en tal forma que por medio de un computador es posible extraer la información deseada. En apoyo de la base de datos, es necesario contar con capacidades adecuadas para capturar los datos, modelar, recuperar, analizar, presentar y diseminar la información (Worboys y Duckham 2004). Una base de datos SIG consiste en una representación espacial de aspectos seleccionados de la superficie o cerca de la superficie de la tierra, construida para servir el propósito de resolver problemas prácticos o de investigación (Longley et al. 2015). Un sistema de información es tan bueno como lo pueden llegar a ser los datos que contiene (Worboys y Duckham 2004).
Cuando trabajamos con SIG también podemos distinguir tres tipos de datos:
- Los atributos son los hechos. En el caso de una parcela, pueden ser el propietario, el número de parcela o los derechos y obligaciones.
- La geometría son las coordenadas del elemento. En el caso de la parcela, se trata de las coordenadas del límite y de medidas como el tamaño y la circunferencia.
- La topología es la ubicación relativa. En una red de carreteras serían las direcciones de giro y las conexiones permitidas.
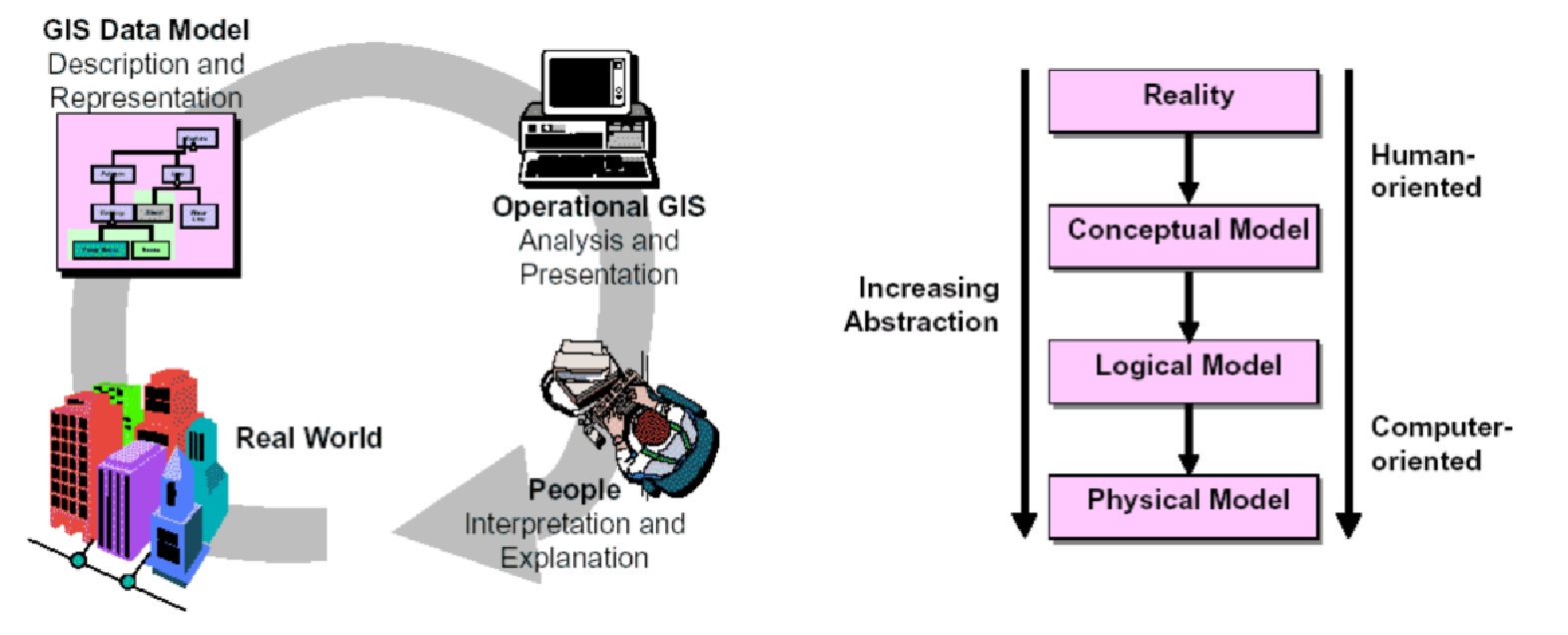
Los aspectos técnicos de la representación de rasgos geográficos involucran el modelamiento de datos. Un modelo de datos es una representación abstracta de la realidad. Es un conjunto de abstracciones para describir y representar partes del mundo real en un sistema informático digital (Figura 6.11). Los modelos de datos son de vital importancia para los SIG porque controlan la forma en que se almacenan los datos y tienen un gran impacto en el tipo de operaciones analíticas que pueden ser ejecutadas. Comenzamos con la realidad, que se compone de fenómenos del mundo real (edificios, personas, lagos, etc.) e incluye aspectos que pueden estar relacionados con una aplicación en particular. El segundo paso consiste en crear un modelo conceptual parcialmente estructurado y orientado al ser humano, que es un modelo de objetos y procesos seleccionados relacionados con el dominio de un problema en particular. El modelo lógico es una representación de la realidad orientada a la implementación, a menudo expresada en forma de diagramas y tablas. Se construye un modelo de base de datos física a partir del modelo de datos lógicos. Este modelo muestra la implementación real en un SIG, que a menudo comprende tablas almacenadas como archivos o bases de datos (Longley et al. 2015).
La recopilación de datos es una tarea importante en los SIG. Los dos métodos principales para la recopilación de datos son la captura de datos y la transferencia de datos. La transferencia de datos implica la importación de datos digitales de otras fuentes. La captura de datos primarios incluye detección remota y levantamiento topográfico, mientras que la captura de datos secundarios implica escaneo, digitalización, vectorización, fotogrametría y construcción de características COGO (geometría de coordenadas) (Longley et al. 2015).
Se distingue entre datos oficiales y datos voluntarios (Figura 6.12). Los datos oficiales son recopilados y proporcionados por una autoridad certificada. Esto significa que los datos se recopilan mediante encuestas y cuestionarios adecuados por parte de las autoridades. Un ejemplo de datos oficiales son los datos del censo que los gobiernos recopilan periódicamente. Los datos oficiales son naturalmente más precisos y dignos de confianza, ya que siguen muchos protocolos.
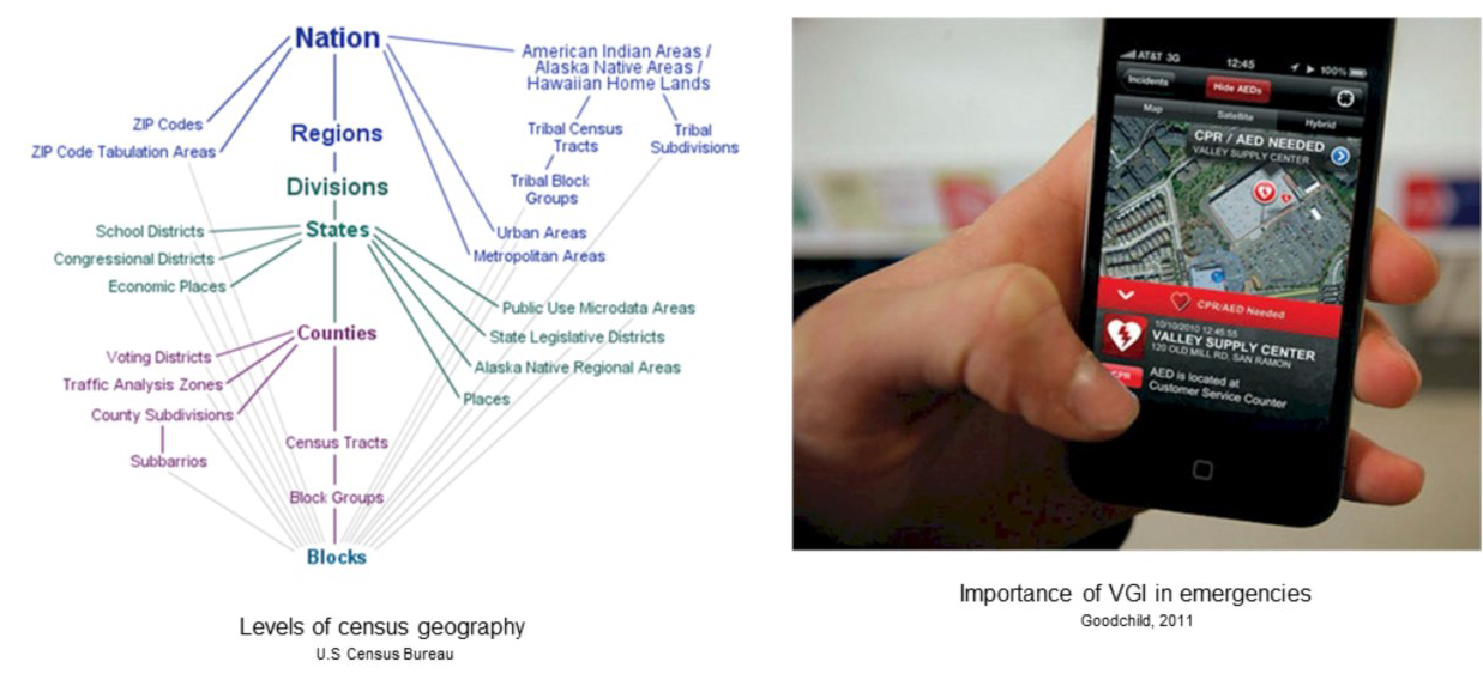
La información geográfica voluntaria (Volunteered Geographic Information - VGI) atrae a ciudadanos individuales al proceso de creación de conocimiento geográfico al involucrarlos en la creación y difusión distribuida de información geográfica (Longley et al. 2015). Como esta información cuenta como contenido generado por el usuario, su precisión puede ser cuestionada. Sin embargo, las aplicaciones VGI como Wikimapia y Open Street Map se están volviendo bastante populares. El VGI se vuelve muy importante durante las emergencias cuando las personas pueden reunir información para tener una idea del alcance de la emergencia.
6.2.5 Procedimientos y Personal (Organización)
Como componente del SIG, la organización incluye procedimientos y personas. Por lo tanto, una organización necesita establecer procedimientos, líneas de informes, puntos de control y otros mecanismos para garantizar que sus actividades SIG se mantengan dentro de los presupuestos, mantengan una alta calidad y, en general, satisfagan las necesidades de la organización. Por último, se necesita gente para diseñar, programar, mantener y suministrar un SIG con datos e interpretar los resultados. Se necesitan varias personas en forma de administradores, gerentes, técnicos de SIG, expertos en aplicaciones, usuarios finales y consumidores (Longley et al. 2015).
Cualquier sistema de información tiene sentido solo en el contexto de una organización. La organización consta de muchas partes complejas y sutiles, pero consideraremos que aquí consiste en un conjunto de objetivos comerciales, un conjunto de procesos comerciales, administración, operadores y el componente general, las personas. Los subcomponentes particulares de la administración, los operadores y las personas son aquellos preocupados por el diseño, implementación y monitoreo del sistema, ya que tienen un papel particularmente importante en la definición de qué es un SIG (Petch 2002). En la composición fotográfica de la Figura 6.13 se puede ver las personas que forman parte del equipo de UNIGIS-Salzburgo.

Antes de poner en marcha el sistema de IG es útil responder a varias preguntas, no siempre obvias:
- Base de datos - ¿cómo está organizada? ¿qué datos se necesitan? ¿qué datos ya existen?
- Estrategia de seguimiento
- Acceso a los datos
- Metainformación sobre la base de datos
- Seguimiento Desarrollo de aplicaciones basadas en el software de IG
- Cualificación y responsabilidades individuales
- Formas de formación y apoyo a los internos
6.3 Flujo de trabajo de un proyecto SIG
Cualquier proyecto SIG consta de al menos cuatro etapas: recopilación, almacenamiento y gestión, análisis y visualización de datos referenciados espacialmente (Figura 6.14).
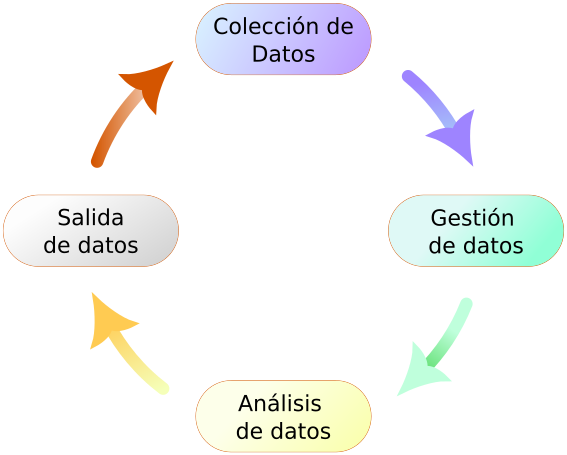
Primero, necesitamos datos. Esto se puede recopilar a través de cuestionarios, encuestas, descargados de un sitio web o comprados. Si los datos son sin procesar, deben limpiarse y organizarse adecuadamente antes de su uso posterior. Una base de datos es a menudo esencial en este nivel porque nos permite almacenar, administrar y recuperar datos de manera eficiente. Una vez que todos los datos requeridos están listos para su uso, se pueden analizar y/o visualizar.
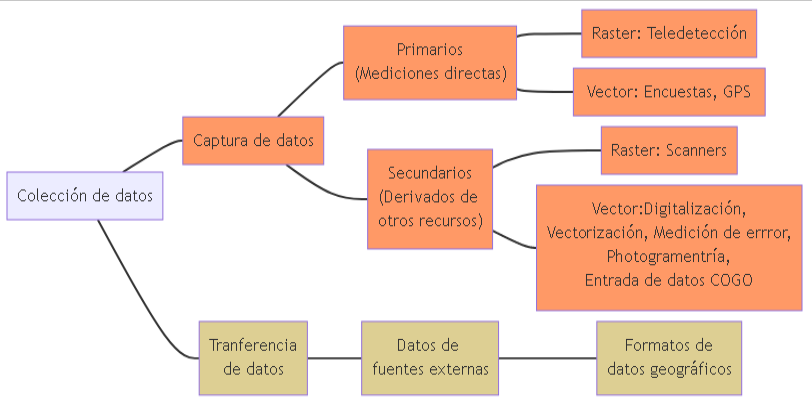
6.3.1 Colecta de datos
El primer paso es la recopilación de datos (Figura 6.15). Consiste tanto en la captura de datos como en la transferencia de datos. Los datos (geográficos) primarios se capturan por medición directa: los métodos de topografía y el GPS producen datos vectoriales; la detección remota da como resultado datos raster. Los datos secundarios se producen mediante digitalización o escaneo. Los mapas son la fuente más común de datos secundarios.
La transferencia de datos se refiere a la obtención de datos de fuentes externas como archivos con diferentes formatos de datos geográficos. La descarga de datos de Internet se ha convertido en una forma común de obtener geodatos.
La recopilación de datos en sí misma es un proyecto con un flujo de trabajo. El primer paso en un flujo de trabajo específico para este proyecto es la planificación. La planificación incluye establecer los requisitos del usuario, reunir recursos como personal, hardware y software, y desarrollar un plan de proyecto. La preparación, especialmente importante en la recopilación de datos, incluye obtener datos, volver a diseñar fuentes de mapas de baja calidad, editar imágenes de mapas escaneadas y eliminar el ruido (datos no deseados, como manchas en un mapa escaneado). Este paso también incluye la configuración de hardware (s) y sistemas de software GIS para recibir los datos adecuadamente.
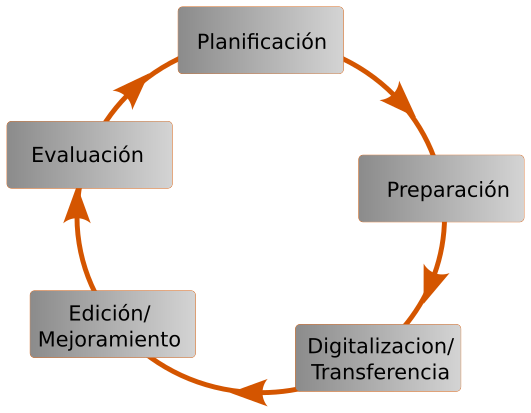
La siguiente etapa, digitalización/transferencia, suele ser el paso más laborioso en la recopilación de datos. Una vez en formato digital, los datos están listos para ser editados y mejorados. Esta etapa incluye validación, corrección de errores y cumplimiento de los estándares de calidad de datos. La etapa final, la evaluación, es el proceso de identificar los éxitos y fracasos del proyecto, tanto cualitativos como cuantitativos. Este flujo de trabajo es iterativo particularmente en proyectos grandes (Longley et al. 2015).
Como ya hemos visto, los datos primarios se capturan por medición directa. La teledetección se refiere a la medición de características físicas, químicas y biológicas de objetos sin contacto directo. Esta tecnología permite procesar datos y crear más información para usar en SIG. Los datos en formato vectorial se capturan mediante técnicas topográficas “clásicas” y GPS. Los instrumentos de topografía como un nivel, teodolito o estación completa determinan una ubicación y elevación en 2-D midiendo ángulos y distancias desde otros puntos conocidos. Sistema de posicionamiento global (GPS), proporciona una ubicación tridimensional en cualquier lugar de la superficie terrestre.
La captura de datos secundarios generalmente se refiere a la conversión de fuentes de datos análogas como mapas e imágenes en un formato digital. Escanear mapas, fotografías aéreas, documentos, etc. da como resultado datos raster (p.e. en un proyecto OpenStreetMap). Los digitalizadores se utilizan para crear datos vectoriales. La fotogrametría, la ciencia y la tecnología para realizar mediciones a partir de fotografías, también genera datos vectoriales como líneas de contorno.
Hay dos formas de recopilar datos, que no siempre se denominan datos secundarios. En primer lugar, la transformación de las bases de datos de direcciones (geocodificación) y, en segundo lugar, el uso de conjuntos de datos que no se hicieron principalmente para este uso, como la obtención de datos de movilidad a partir de tweets geocodificados (como explica este artículo).
6.3.2 Calidad de los datos
Dado que la calidad de los datos resultantes nunca puede ser superior a la de los datos de entrada, el control de calidad es una parte esencial del flujo de trabajo del SIG. Hay que distinguir entre la “aptitud para el uso” y la calidad básica de los datos. La norma ISO 19157 es una buena síntesis de los diferentes enfoques de evaluación de la calidad.
- El control de calidad externo utiliza conjuntos de datos externos y verificados para su comparación.
- El control de calidad interno comprueba la coherencia de la estructura interna del conjunto de datos. Ejemplo: La calidad de un grafo de calles puede comprobarse sin un conjunto de datos de referencia. Lea este artículo del blog para obtener más detalles.
Se supone que los metadatos son la fuente de “datos sobre los datos”. Lamentablemente, no siempre se proporcionan. Por lo general, los metadatos contienen información sobre el autor, las manipulaciones, las restricciones (como licencias o derechos de autor) y la precisión de los datos.
6.3.3 Gestión de datos
Es importante pasar por el proceso de conceptualización y modelización de los datos antes de introducirlos en una base de datos. Esto ayuda a visualizar mentalmente el resultado final y también a garantizar que las tablas o campos importantes se incluyan en el conjunto de datos.
Un modelo de datos es un conjunto de construcciones para describir y representar aspectos seleccionados del mundo real en un sistema digital. Los modelos de datos controlan la forma en que se almacenan los datos y definen el tipo de operaciones analíticas que pueden realizarse. En los primeros años, los SIG empezaron como una extensión de los modelos de datos gráficos y de imágenes simples de CAD (Longley et al. 2015, 207).
Para que los datos puedan ser utilizados, deben ser transformados en formatos compatibles y eficaces. Cuando se utilizan datos láser, las nubes de puntos tienen que transformarse para convertirse en un modelo 3D completo. En la Figura 6.17 se muestra brevemente este proceso (para más detalles, lea este artículo)

Cuando se capturan datos secundarios, es crucial para el procesamiento posterior comprobar a fondo los metadatos (como el sistema de referencia espacial) y verificar semánticamente los datos de los atributos.
Cualquier sistema SIG es tan bueno como los datos que contiene. Esta frase es muy cierta y la afirma ESRI en su sitio de gestión de datos. Aunque los datos espaciales sólo se utilicen una vez -aunque casi nunca sea así-, es esencial mantener los datos “limpios”. La importancia de una gestión eficaz de los datos aumenta con el tamaño de la empresa, la intensidad del proyecto y la integración global en la estructura informática de la organización.
Hasta hace un par de años, esto era una tarea sencilla; los datos espaciales se guardaban en forma de archivos. Más tarde, las bases de datos relacionales y las estructuras servidor-cliente evolucionaron como alternativas. Todas estas herramientas de gestión de datos siguen utilizándose, pero han sido sustituidas por estructuras más complejas. Dos palabras clave relacionadas son Infraestructura de Datos Espaciales (IDE) y SIG en la nube. Estos temas se tratarán con más detalle en módulos posteriores de su carrera en UNIGIS.
Debido a la creciente cantidad de datos - en su mayoría con un componente espacial - la tecnología ha progresado rápidamente. Así, el tema de la gestión de datos espaciales es un tema de investigación vibrante que se centra en:
Las bases de datos relacionales y orientadas a objetos no pueden procesar los grandes datos (Big Data).
Debido al uso multidisciplinar de los SIG y los datos espaciales, es necesario establecer nuevas ontologías.
6.3.4 Análisis espacial
El análisis espacial es una de las partes centrales y críticas de cualquier sistema SIG, el medio de agregar valor a los datos geográficos y de convertir los datos en información útil. El análisis espacial se puede utilizar para promover los objetivos de la ciencia al revelar patrones que no fueron reconocidos previamente y que alude a generalidades y leyes no descubiertas. El famoso ejemplo del análisis espacial del cólera de John Snow (Figura 6.18) muestra que los patrones espaciales en la aparición de una enfermedad pueden insinuar los mecanismos que la causan.
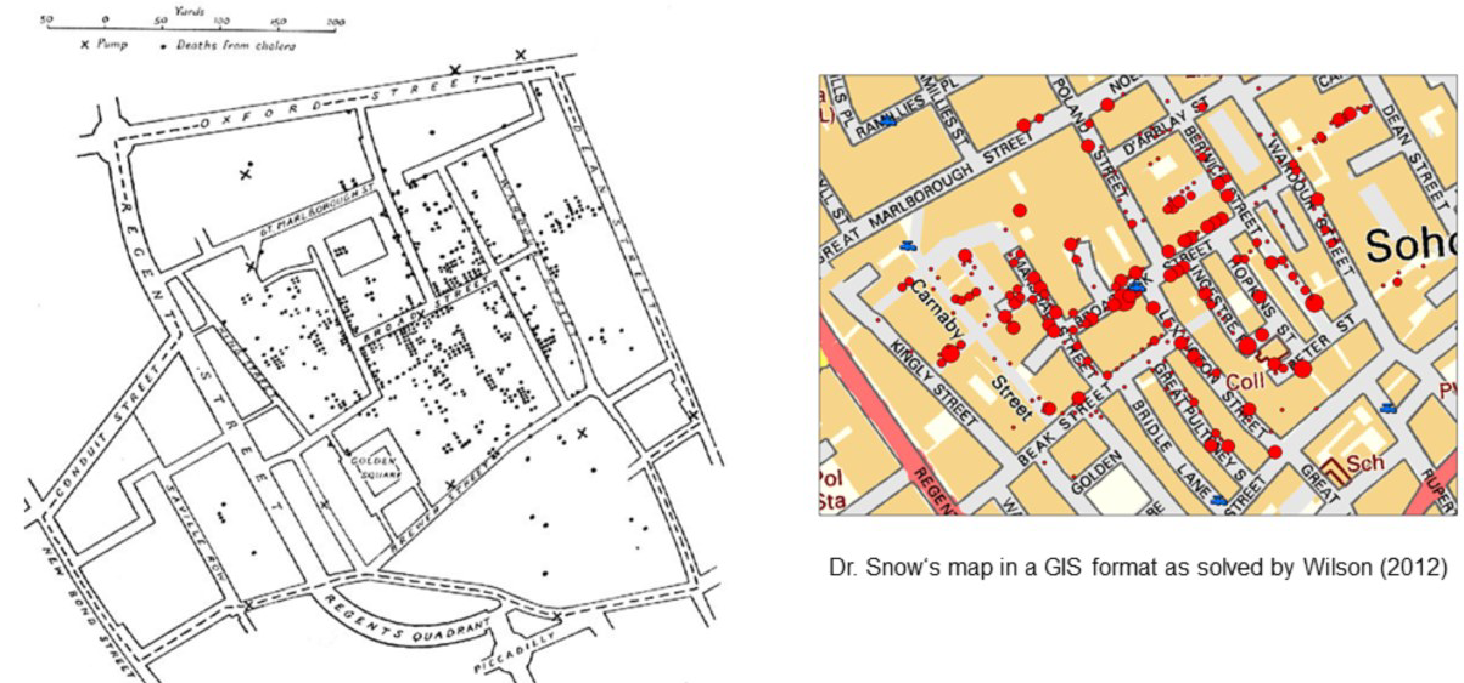
La ubicación proporciona una clave común entre los conjuntos de datos, lo que permite descubrir relaciones y correlaciones entre las propiedades de los lugares. La distancia define la separación de lugares en el espacio geográfico y actúa como una variable importante en muchos de los procesos que impactan el paisaje geográfico. Las áreas definen el contexto vecinal de procesos y eventos, y también capturan el importante concepto de escala. Este vídeo muestra un ejemplo de una herramienta de análisis espacial.
La base del análisis espacial son principalmente dos conceptos: la intersección y la indagación, en un contexto explícitamente espacial. La intersección se basa en el concepto de colocar dos (o más) capas temáticas una encima de otra y combinarlas en función de su contexto espacial, es decir, hacer una superposición (véase la Figura 6.19).
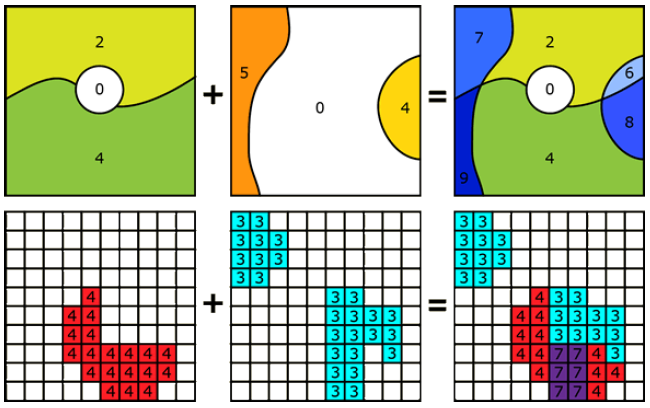
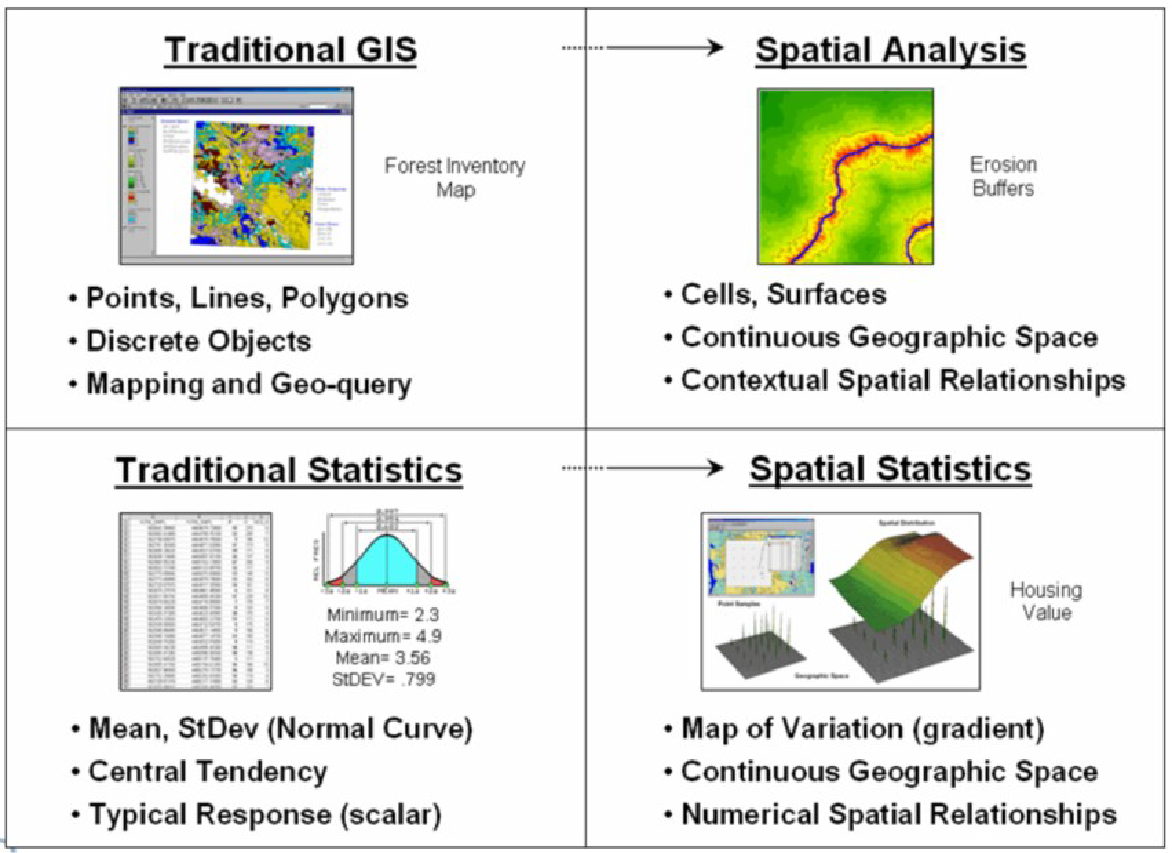
Los SIG tradicionales tratan el espacio geográfico de la misma manera que los mapas en papel. Utilizan puntos, líneas y polígonos para describir varios objetos discretos como casas, arroyos y lagos. Estos objetos están vinculados a atributos en una tabla desde donde es posible hacer geo-consultas complejas de los datos y luego mapear los resultados. El análisis espacial extiende el conjunto básico de características de mapas discretos en un espacio geográfico continuo como un conjunto de celdas de cuadrícula (Figura 6.20). Este método ayuda a crear relaciones espaciales contextuales como la distancia efectiva, la ruta óptima, etc. Además, proporciona una dimensión matemática al espacio geográfico. En las estadísticas tradicionales, los resultados se muestran en papel y en números. Sin embargo, las estadísticas espaciales intentan mapear la variación en los datos (por ejemplo, la desviación de un valor medio en el conjunto de datos) en lugar de los datos en sí. Con el análisis se crean relaciones espaciales numéricas (Berry 2004).
6.3.5 GeoDiseño
El análisis de datos espaciales generalmente se realiza para descubrir anomalías/patrones o probar hipótesis. Sin embargo, los datos espaciales también se pueden analizar con el objetivo de crear diseños mejorados, como minimizar la distancia de viaje, minimizar los costos de construcción o maximizar las ganancias.
Esto es ayudado por métodos normativos, que son métodos desarrollados para su aplicación a la solución de problemas prácticos de diseño. Los métodos normativos aplican objetivos bien definidos al diseño de sistemas (Longley et al. 2015).
Los métodos de diseño se implementan como componentes de sistemas construidos para soportar la toma de decisiones (sistemas de soporte de decisión espacial, SDSS). Las decisiones complejas a menudo son problemáticas ya que tienen muchas partes interesadas (actores) interesados en el resultado y en defender una posición u otra. Los SDSS son SIG especialmente adaptados que se pueden utilizar durante el proceso de toma de decisiones para proporcionar comentarios instantáneos sobre las implicaciones de varias propuestas y la evaluación de casos de uso. GeoDesign usa puntos de ubicación y problemas de enrutamiento para encontrar soluciones óptimas. Un SIG puede ser una herramienta muy efectiva para resolver problemas de enrutamiento porque permite examinar grandes cantidades de posibles soluciones rápidamente (Longley et al. 2015).
6.3.6 Comunicación
Después de integrar y analizar los datos, es esencial presentar los resultados de forma visual. Por lo tanto, ya sabemos -al menos en teoría- cómo se puede realizar un proyecto de este tipo. Una cuestión importante que ustedes, como (futuros) expertos en SIG, tendrán que responder antes de ejecutar el primer paso del flujo de trabajo es la elección de la funcionalidad SIG adecuada. Los mapas, diagramas y figuras han demostrado ser una forma adecuada de presentar el resultado del análisis espacial.
El análisis y el resultado de los datos del SIG dependen en gran medida del uso que se les dé y del público al que se dirijan. Por lo tanto, es importante decidir qué se va a mostrar en el resultado y cómo, y a quién va dirigido. En función de ello, se pueden elaborar folletos, mapas impresos de gran tamaño o Storymaps que combinen información espacial con entradas textuales para servicios web.
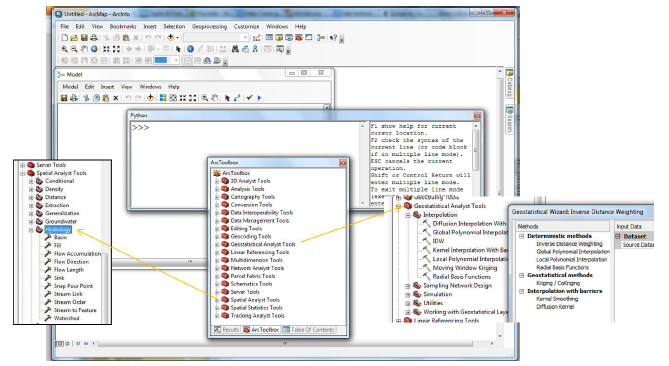
Tomemos como ejemplo ArcGIS (véase la Figura 6.21), ya que es uno de los sistemas SIG más extendidos. ArcGIS dispone de herramientas diseñadas para ayudar en tareas específicas. Por ejemplo, para analizar y resolver espacialmente un problema relacionado con la hidrología, se puede utilizar la opción Hydrology en Analysis tools.
Este conjunto de herramientas permite trabajar con la cuenca, el relleno, la dirección del flujo, sumideros, etc. para representar los aspectos hidrológicos de un lugar. Una tarea relacionada con la geoestadística puede resolverse utilizando Geostatistical Analyst Tools. Network Analyst ofrece herramientas para modelar y resolver problemas de redes. Si en ArcGIS una tarea no puede manejarse utilizando las funciones/herramientas estándar disponibles, su solución puede programarse utilizando Model Builder y scripts de Python.
En esta lección hemos discutido un flujo de trabajo típico de un proyecto en Geoinformática y hemos aprendido que el análisis de datos espaciales es un proceso iterativo. Esto significa que difícilmente existe una única forma correcta o una única solución correcta. Es crucial utilizar varios conceptos adecuados para la cuestión específica con el fin de obtener un resultado adecuado.